In this post, we show the demo of PMVC: Data Augmentation-Based Prosody Modeling for Expressive Voice Conversion
Overview
Voice conversion as the style transfer task applied to speech, refers to converting one person's speech into a new speech that sounds like another person's. Up to now, there has been a lot of research devoted to better implementation of VC tasks. However, a good voice conversion model should not only match the timbre information of the target speaker, but also expressive information such as prosody, pace, pause, etc. In this context, prosody modeling is crucial for achieving expressive voice conversion that sounds natural and convincing. Unfortunately, prosody modeling is important but challenging, especially without text transcriptions. In this paper, we firstly propose a novel voice conversion framework named `PMVC', which effectively separates and models the content, timbre, and prosodic information from the speech without text transcriptions. Specially, we introduce a new speech augmentation algorithm for robust prosody extraction. And building upon this, mask and predict mechanism is applied in the disentanglement of prosody and content information. The experimental results on the AIShell-3 corpus supports our improvement of naturalness and similarity of converted speech.
Model Architecture
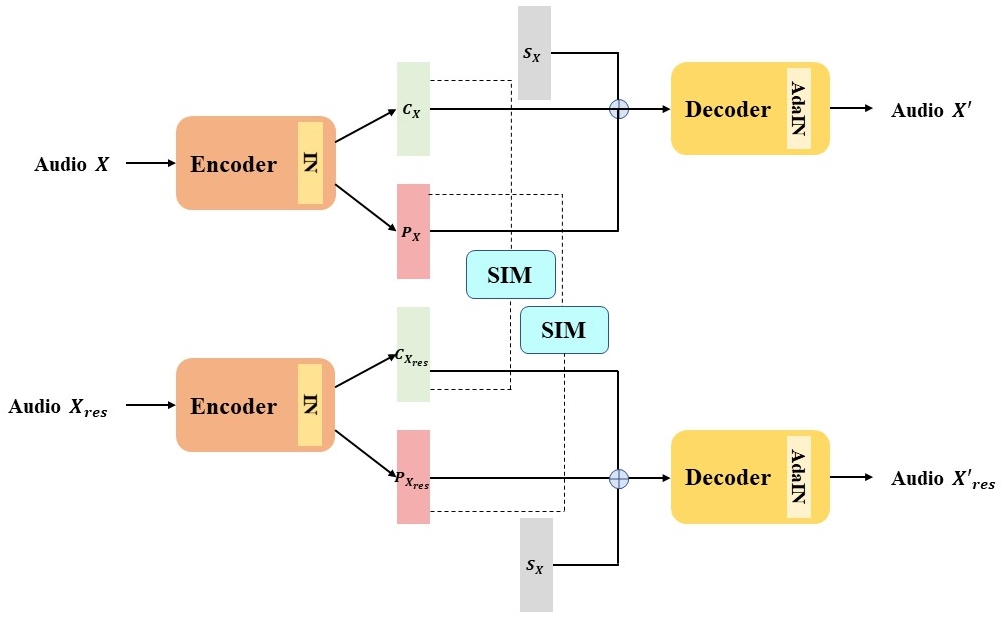 |
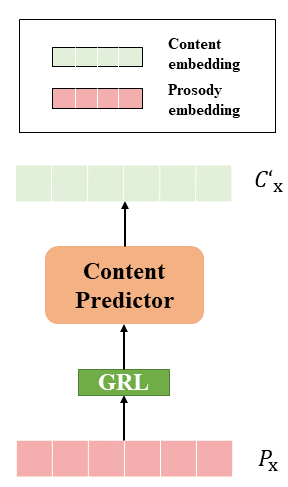 |
The image on the right displays the content predictor, and it's reasonable to anticipate a strong correlation between the predicted content embedding and the actual content. GRL means Gradient Reversal Layer, it will make the optimization goal of the feature encoder and the content predictor completely opposite.
Demos
We provide audio demo of
| ID | Source speech of speaker SSB0005 | Augmented speech based on RR | Augmented speech based on RP |
|---|---|---|---|
| 01 | |||
| 02 | |||
| 03 | |||
| 04 | |||
| 05 | |||
| 06 | |||
| 07 | |||
| 08 | |||
| 09 | |||
| 10 |
| ID | Type | Source | Target | Coverted_PMVC | Coverted_Speechflow | Coverted_autoVC |
|---|---|---|---|---|---|---|
| 01 | F-M | |||||
| 02 | M-F | |||||
| 03 | M-M |